用 AI 一周写 71 万行 Go:ETH2030 以太坊客户端技术解析
本文基于 jiayaoqijia/eth2030 仓库源码分析编写。
引言
2026 年 2 月 25 日,开发者 YQ 在 X 上宣布:他用 Claude Code(Opus 4)在大约一周时间内,完成了一个面向以太坊 2030 路线图的实验性执行客户端 —— ETH2030。
数字很惊人:
| 指标 | 数据 |
|---|---|
| Go 源文件 | 1,909 个 |
| 代码行数 | ~713K |
| 包数量 | 50 个 |
| 测试数量 | 18,257 个 |
| 支持 EIP | 58+ |
| EF 状态测试 | 36,126 / 36,126(100%) |
| API 调用 | 26,798 次 |
| Token 消耗 | 27.7 亿 |
| 估算 API 成本 | ~$5,750 |
这不是一个玩具 demo。它有完整的 EVM 实现、共识层、数据可用性层、后量子密码学、zkVM 框架,甚至能连接 go-ethereum 同步主网。
这篇文章分两部分:第一部分系统讲解以太坊 2030 路线图的技术方向 —— 以太坊想解决什么问题、为什么需要这些技术;第二部分深入 ETH2030 的代码,看它如何将这些理论变成可运行的 Go 实现。
第一部分:以太坊 2030 路线图
从 Strawmap 说起
以太坊基金会 Protocol 团队维护了一张 L1 Strawmap(路线图草案),规划了从 2026 到 2030+ 的升级路径。
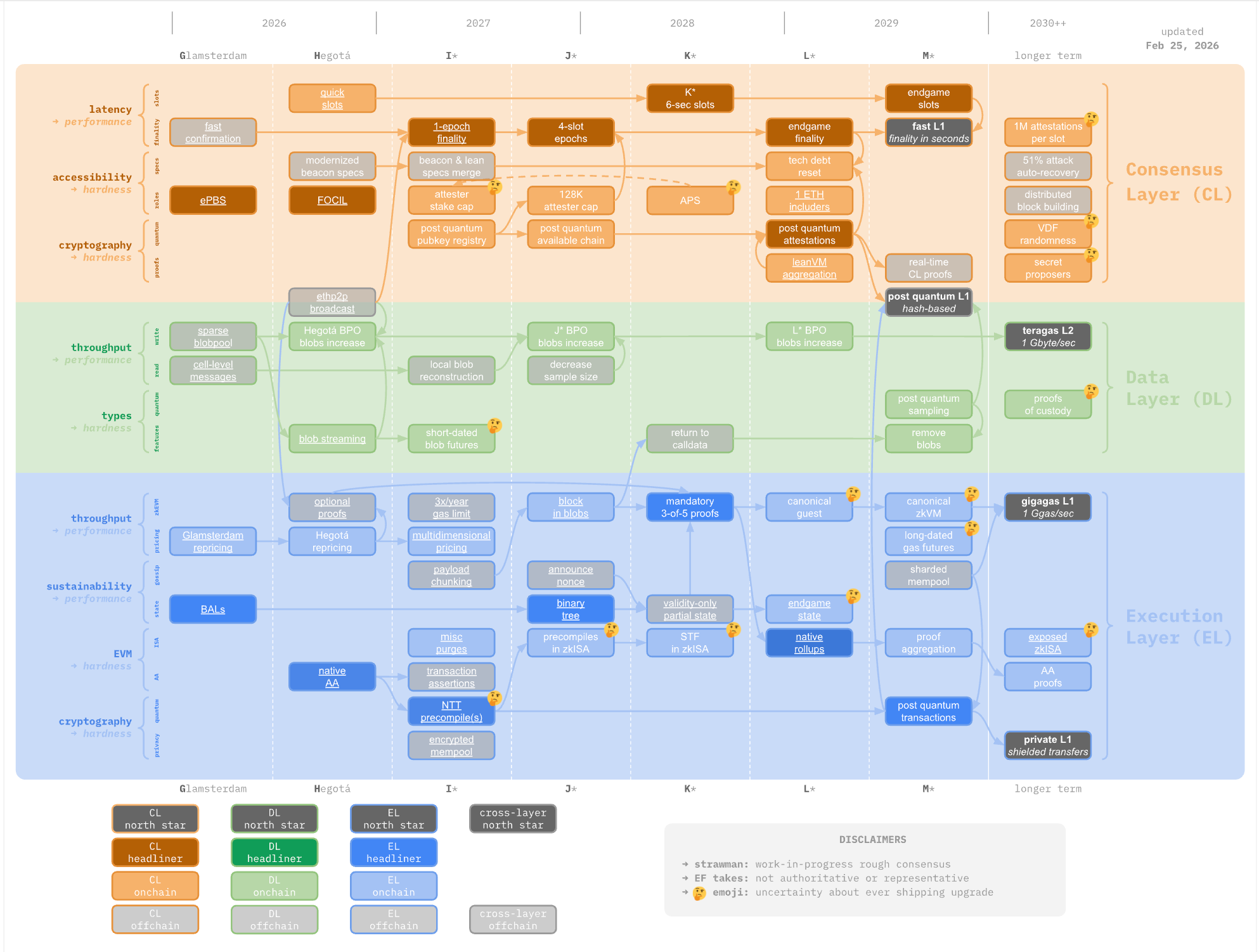 _以太坊 L1 Strawmap — EF Protocol 团队维护,strawmap.org_它不是官方承诺,而是一个”加速主义协调工具” —— 给所有客户端团队一个共同的方向参考。
_以太坊 L1 Strawmap — EF Protocol 团队维护,strawmap.org_它不是官方承诺,而是一个”加速主义协调工具” —— 给所有客户端团队一个共同的方向参考。
路线图分三层,八个升级阶段:
| 阶段 | 大约时间 | 核心主题 |
|---|---|---|
| Glamsterdam | 2026 | ePBS、FOCIL、BAL 并行执行 |
| Hegotá | 2026-27 | PeerDAS、后量子密钥注册、gas repricing |
| I* | 2027 | 多维 gas、加密内存池、native AA |
| J* | 2027-28 | 4-slot epochs、binary tree、blob futures |
| K* | 2028 | 6 秒 slot、APS、mandatory proofs |
| L* | 2028-29 | endgame finality、native rollups、zkVM |
| M* | 2029 | fast L1(秒级确认)、proof aggregation |
| longer term | 2030++ | gigagas L1、teragas L2、隐私 L1 |
三层分别是:
- Consensus Layer (CL) — 橙色区域:延迟、共识安全、密码学
- Data Layer (DL) — 绿色区域:blob 吞吐量、数据可用性
- Execution Layer (EL) — 蓝色区域:执行吞吐量、EVM 演进、零知识证明
最终的五个北极星目标是:
| 目标 | 含义 |
|---|---|
| Fast L1 | 交易包含和链确认在秒级完成 |
| Gigagas L1 | L1 每秒 1 Gigagas(~10K TPS),通过 zkEVM 和实时证明 |
| Teragas L2 | L2 每秒 1 GB(~10M TPS),通过数据可用性采样 |
| Post-Quantum L1 | 百年级密码学安全,基于哈希方案 |
| Private L1 | 隐私作为一等公民,通过 L1 屏蔽转账 |
接下来逐一拆解每个核心技术方向。
1. 共识层:从 15 分钟到 3 个 Slot
当前痛点: 以太坊的 Gasper 共识需要 2 个 epoch(约 12.8 分钟)才能达到最终性。用户提交交易后,虽然 1 个 slot(12 秒)就能被包含在区块中,但要等到”这个区块绝对不会被回滚”,需要漫长的等待。对于跨链桥和 DeFi 来说,这个延迟是巨大的安全风险。
3-Slot Finality (3SF) 的目标是将最终性缩短到 3 个 slot(约 36 秒)。核心思路是改变投票机制:
- 当前:验证者被分成 32 个委员会,分布在一个 epoch 的 32 个 slot 中。要收集完所有委员会的投票才能确认。
- 3SF:每个 slot 都收集足够多验证者的投票。当 2/3 的质押权重对同一个区块投票后,立即确认。
这就引出了一系列配套改进:
- Quick Slots(6 秒出块):将 slot 时间从 12 秒缩短到 6 秒,进一步降低延迟
- 128K Attester Cap:限制每个 slot 的验证者数量为 128K,控制聚合签名的计算开销
- 1 ETH 最低质押:将最低质押从 32 ETH 降至 1 ETH,增加验证者数量和去中心化程度
- APS(Attester-Proposer Separation):将”打包交易”和”投票确认”的角色分开,避免利益冲突
2. 提议者-构建者分离:ePBS + FOCIL
当前痛点: 以太坊的区块构建已经高度中心化。目前 ~90% 的区块由 2-3 个构建者(如 Beaver Build、Titan Builder)通过 MEV-Boost 构建。这个系统依赖信任假设 —— 中继需要被信任不会审查交易或偷取 MEV。
ePBS(Enshrined Proposer-Builder Separation,EIP-7732) 将构建者-提议者分离写入协议层:
1
2
3
4
5
当前流程(MEV-Boost,协议外):
Builder → Relay → Proposer → 区块上链
ePBS 流程(协议内):
Builder 提交出价 → 协议内竞拍 → 最高价构建者获得构建权 → 区块上链
消除了对中继的信任依赖,但有一个新问题:如果构建者可以自由选择包含哪些交易,他们就可以审查交易。
FOCIL(Fork-Choice Enforced Inclusion Lists,EIP-7805) 解决审查问题:
- 每个 slot,一组验证者各自生成一份”包含列表” —— 他们认为应该被包含的交易
- 构建者必须包含这些列表中的交易,否则他的区块会被 fork choice 拒绝
- 这样即使构建者想审查某笔交易,验证者的包含列表会强制将其纳入
ePBS + FOCIL 组合 = 去信任的区块构建 + 抗审查保障。
3. 数据可用性:PeerDAS
当前痛点: EIP-4844(Dencun 升级)引入了 blob 交易,但每个区块只有 ~128KB 的 blob 空间。对于 Rollup 来说远远不够 —— 理想目标是每秒 1GB 的数据吞吐量(Teragas)。
直接增大区块中的 blob 数据有个根本问题:每个节点都要下载全部数据。如果每个区块有 1GB,家用节点根本无法参与。
PeerDAS(Peer Data Availability Sampling,EIP-7594) 的解法是:不要求每个节点下载全部数据,只要求采样一小部分。
工作原理:
- 纠删码编码:将 blob 数据用 Reed-Solomon 纠删码编码,从 N 列扩展到 2N 列。只要拿到任意 N 列,就能恢复全部数据。
- Custody Groups:验证者被分到不同的 custody group,每个组负责保存一部分列。
- 随机采样:节点随机选择几列进行采样。如果能成功获取到,就有很高的概率说明完整数据是可用的(恶意构建者要隐藏数据,必须隐藏超过 50% 的列,那么采样失败的概率极高)。
1
2
3
4
5
6
7
8
9
原始 Blob: [C1] [C2] [C3] [C4]
↓ Reed-Solomon 扩展
编码后: [C1] [C2] [C3] [C4] [C5] [C6] [C7] [C8]
↓ 分配给不同 custody group
Group A: [C1] [C5]
Group B: [C2] [C6]
Group C: [C3] [C7]
Group D: [C4] [C8]
↓ 任意取 4 列即可恢复
路线图后期还有:
- Variable-size Blobs:可变大小的 blob,适应不同 Rollup 的需求
- Blob Streaming:流式传输 blob 数据,降低延迟
- Post-Quantum Blobs:用后量子密码学保护 blob 的 KZG 承诺
4. 并行执行:Block Access Lists (EIP-7928)
当前痛点: 以太坊的 EVM 是严格顺序执行的 —— 区块中的交易必须一笔一笔按顺序执行。即使两笔交易完全不相关(一个操作 Uniswap,另一个操作 Aave),也不能并行。这是吞吐量的根本瓶颈。
Solana 通过 Sealevel 实现了并行执行,但它的方案是编译时确定依赖。以太坊选择了另一条路:
Block Access Lists(BAL,EIP-7928) 要求交易声明自己会访问的状态:
- 交易声明:每笔交易附带一个 access list,列出它会读写的账户地址和存储槽
- 依赖分析:区块构建者分析所有交易的 access list,构建依赖图
- 并行调度:没有 access list 交集的交易可以并行执行
- 状态合并:并行执行完成后合并 state changes
一个具体例子:
1
2
3
4
5
6
7
8
交易 A: 操作 Uniswap V3 的 USDC/ETH 池 → access list: [UniswapPool, USDC, WETH]
交易 B: 向某地址转 10 ETH → access list: [sender, receiver]
交易 C: 操作 Aave 借贷 → access list: [AavePool, DAI]
A 和 B 无交集 → 可并行
A 和 C 无交集 → 可并行
B 和 C 无交集 → 可并行
→ A、B、C 可以全部并行执行
理论上,这可以将吞吐量提升数倍,最终目标是 Gigagas(每秒 10 亿 gas,约 10K TPS)。
5. 零知识证明:zkVM + Proof Aggregation
当前痛点: 全节点需要重新执行每笔交易来验证区块的正确性。这意味着验证一个区块的成本和执行它一样高。随着吞吐量增加,验证成本也线性增长。
zkVM 的解法是:用零知识证明替代重复执行。 区块生产者执行交易并生成一个证明,验证者只需验证证明(毫秒级)就能确认整个区块的正确性。
路线图中的 zkVM 分三步走:
| 阶段 | 特性 | 含义 |
|---|---|---|
| Canonical Guest | 标准化 zkVM 的”客程序”格式 | 所有客户端团队写同一份状态转换代码 |
| STF in zkISA | 状态转换函数编译为 zkVM 指令集 | EVM 执行可以被证明 |
| Canonical zkVM | 确定官方的 zkVM 实现 | RISC-V 或自定义指令集 |
配套的证明系统:
- Optional Proofs(I* 阶段):区块可以附带证明,但不强制
- Mandatory 3-of-5 Proofs(K* 阶段):每个区块必须附带至少 3 种不同方案的证明
- Proof Aggregation(M* 阶段):多个证明聚合为一个,降低验证开销
为什么要 3-of-5?因为单一证明方案可能存在未知漏洞。要求 3 种独立方案(如 SNARK + STARK + IPA)同时通过,大幅降低系统风险。
6. 后量子密码学
当前痛点: 以太坊的签名方案(ECDSA on secp256k1、BLS12-381)基于椭圆曲线离散对数难题。量子计算机可以用 Shor 算法在多项式时间内破解。虽然大规模量子计算机可能还需要 10-20 年,但”先窃取,后解密”的威胁已经存在。
路线图的后量子迁移分三阶段:
- Post-Quantum Public Key Registry(Hegotá):验证者注册后量子公钥,为迁移做准备
- Post-Quantum Attestations(L*):共识层的 attestation 改用后量子签名
- Post-Quantum L1(M*):全面迁移,包括用户交易签名
候选方案:
| 算法 | 类型 | 特点 |
|---|---|---|
| ML-DSA (Dilithium) | 格密码 | NIST 标准,签名较大(~2.4KB)但速度快 |
| Falcon | 基于 NTRU 格 | 签名更紧凑(~700B)但实现复杂 |
| SPHINCS+ | 基于哈希 | 最保守,仅依赖哈希函数安全性,签名最大(~7KB) |
实际迁移中可能使用 Hybrid 模式:每笔交易同时带 ECDSA 和后量子签名,实现向后兼容的渐进迁移。
7. Native Rollups (EIP-8079)
当前痛点: Rollup 是以太坊扩容的核心策略,但目前的 Rollup 架构是”外挂”式的:L2 需要自己实现排序器、证明系统、跨链桥。每个 Rollup 都是一个独立系统,碎片化严重。
Native Rollups 将 Rollup 支持写入 L1 协议:
- EXECUTE 预编译:L1 合约可以直接调用一段代码在隔离的 L2 环境中执行,并获得执行结果
- Anchor Contract:每个 L2 在 L1 上有一个锚定合约,管理状态根和跨链消息
这意味着 L2 不再需要独立的证明系统和结算逻辑 —— L1 原生支持。Rollup 变得像部署一个智能合约一样简单。
小结
将这些技术方向放在一起看:
graph TB
subgraph "当前以太坊的瓶颈"
F1[最终性太慢 ~15min]
F2[区块构建中心化]
F3[顺序执行瓶颈]
F4[全节点验证太重]
F5[量子计算威胁]
F6[Rollup 碎片化]
F7[数据空间不足]
end
subgraph "2030 路线图解法"
S1[3SF → 36秒最终性]
S2[ePBS + FOCIL → 去信任构建 + 抗审查]
S3[BAL → 并行执行 → Gigagas]
S4[zkVM → 证明替代执行]
S5[PQ Crypto → 格密码迁移]
S6[Native Rollups → 协议原生支持]
S7[PeerDAS → 采样替代全量下载]
end
F1 --> S1
F2 --> S2
F3 --> S3
F4 --> S4
F5 --> S5
F6 --> S6
F7 --> S7
这就是 ETH2030 试图实现的全景。接下来我们进入代码。
第二部分:ETH2030 代码解析
第一部分讲了”以太坊想做什么”,这一部分看 ETH2030 是怎么把这些想法变成 Go 代码的。不逐包罗列,而是聚焦几个有意思的设计决策。
最聪明的决策:站在 go-ethereum 的肩膀上
从零写一个能跑通 36,126 个 EF 状态测试的 EVM 需要多久?go-ethereum 用了十年。ETH2030 的做法是:不重复造这个轮子。
pkg/geth/ 是整个项目里最短的包 —— 只有 8 个文件、~50KB。但它是最关键的。这个薄适配层将 go-ethereum v1.17.0 作为 Go module 直接引入,用 gethcore.ApplyMessage() 执行交易,然后通过 evm.SetPrecompiles() 注入 ETH2030 自定义的 13 个预编译合约(NTT、NII 字段运算等 2030 路线图需要的新预编译)。
这个决策解锁了两件事:
- 立即获得 100% EF 合规 — 不用自己处理 SSTORE gas 计量的 17 种边界情况、不用实现 EIP-158 空账户清理、不用调试 CREATE2 地址冲突。这些是真正吃人的细节。
- 可以专注于 2030 特性 — 共识层、DAS、ePBS、zkVM,这些是路线图的核心,也是 ETH2030 真正要探索的领域。
go.mod 只有 5 个直接依赖,eth2030-geth 二进制已验证可连接 Sepolia 测试网以 ~9K headers/sec 同步。
与此同时,ETH2030 在 pkg/core/vm/ 也保留了一套完整的原生 EVM(164+ 操作码、24 个预编译、EOF 支持)。两套 EVM 并存:geth 集成层用于真实网络同步,原生实现用于研究和扩展。 这是一个很务实的分层。
用代码建模共识:从 Gasper 到 3SF
pkg/consensus/ 是最大的包(201 个文件,2.2MB),但它的核心逻辑反而很紧凑。
3SF 的本质是:每个 slot 都做一次投票,够了就立刻确认,不用等一整个 epoch。 ETH2030 的 SSF 引擎(ssf.go)正是这个思路 —— 每个 slot 维护一个投票跟踪器,按 block root 累加质押权重,一旦某个 root 超过 2/3 就标记 finalized。
有意思的是围绕这个核心展开的模块设计。共识不是一个孤立的投票器,它需要:
- 谁来投票? →
committee_rotation.go动态轮换验证者委员会 - 投票怎么传播? →
attestation_aggregator.go聚合去重 - 出块变快了怎么办? →
quick_slots.go处理 6 秒 slot 下的时序问题 - 分叉了选哪条链? →
forkchoice.go实现 LMD-GHOST - epoch 到了做什么? →
epoch_transition.go处理 shuffle、奖惩、余额更新
这些模块各自独立,但通过共享的 BeaconState 类型串联起来。这种建模方式有一个价值:它把共识 spec 中散落在各处的文字描述,变成了可以追踪依赖关系的代码。 比如你想知道”6 秒 slot 对 attestation 聚合有什么影响”,在 spec 里要对照多个文档,在代码里直接看调用链就行。
格密码的完整实现
pkg/crypto/pqc/ 是技术密度最高的部分。ETH2030 没有简单地封装一个 PQ 库,而是从多项式运算开始实现了 Dilithium-3:
- 多项式环 Z_q[X]/(X^N+1) 上的运算,参数 N=256, Q=8380417
- NTT 加速多项式乘法
- Fiat-Shamir with Aborts 签名流程(拒绝采样 —— 如果签名泄露了私钥信息就丢弃重来)
- 完整的 keygen → sign → verify 流程
除 Dilithium 外还实现了 Falcon512(NTRU 格)、SPHINCS+(纯哈希)和 ML-DSA-65(FIPS 204)。
更值得注意的是 Hybrid Signer —— 同时生成 ECDSA 和后量子签名,验证时两个都过才算通过。这不只是一个技术 demo,而是路线图中实际的迁移策略:在量子计算机还不够强的过渡期,hybrid 模式让系统同时受到经典和后量子两套密码学的保护。
RISC-V 模拟器:zkVM 的基石
zkVM 的落地需要先回答一个问题:用什么指令集? 以太坊社区的共识是 RISC-V,因为它开放、简单、工具链成熟。
ETH2030 在 pkg/zkvm/riscv_cpu.go 里实现了一个 RV32IM 模拟器 —— 32 个通用寄存器、完整的 R/I/S/B/U/J 类型指令解码、M 扩展(乘除法)。关键的是它不仅仅是一个 CPU 模拟器,还集成了 witness 收集 —— 每条指令执行时记录输入输出,这些 witness 是后续生成零知识证明的原材料。
围绕这个模拟器,还构建了:
- Poseidon 哈希(ZK-friendly 的哈希函数,在证明电路中比 SHA-256 高效几个数量级)
- STF 执行器(将以太坊状态转换编译为 RISC-V 程序执行)
- 3-of-5 证明聚合(
pkg/proofs/,支持 SNARK/STARK/IPA/KZG 四种证明方案,要求至少 3 种通过)
这个证明聚合框架直接对应了路线图中 K* 阶段的”mandatory 3-of-5 proofs” —— 用多方案冗余来对冲单一证明系统的未知漏洞风险。
PeerDAS:纠删码 + 采样的工程实现
pkg/das/ 的核心在 erasure/ 子包 —— 一个基于有限域 Lagrange 插值的 Reed-Solomon 编解码实现。原理在第一部分已经讲过,这里看工程层面:
ETH2030 将 DAS 拆成了清晰的管道:
1
Blob → Reed-Solomon 编码 → 列分配(Custody Group) → 采样验证 → 恢复
每一步都是独立可测的模块。sampling.go 根据 node ID 计算 custody group 到列索引的映射;custody_proofs.go 处理证明生成和验证;blob_streaming.go 解决大 blob 的流式传输问题;futures.go 实现了 blob 空间的提前预定机制。
这种拆法让每个模块都可以单独跑测试,也让读者可以逐层理解 PeerDAS 从 spec 到实现的映射。
ePBS + FOCIL:两个互锁的协议
ePBS 和 FOCIL 的实现虽然分属两个包,但它们在概念上是互锁的 —— ePBS 解决”谁来构建区块”(协议内竞拍替代 MEV-Boost),FOCIL 解决”如何防止构建者审查”(验证者强制包含列表)。
ETH2030 的 pkg/epbs/auction.go 将构建者出价排序后选最高者;pkg/focil/ 的 compliance check 确保选出的构建者必须包含验证者指定的交易。两个包通过共享的 Block 类型交互 —— 构建者构建的 payload 必须满足 FOCIL 约束才能被接受。
数字背后的架构
回过头看 ETH2030 的 50 个包,一个有趣的观察是:它们之间的依赖关系基本是单向的。
底层包(rlp、ssz、crypto)不依赖任何其他包。中间层(core/vm、core/state、trie)只依赖底层。上层协议(consensus、das、epbs、focil)依赖中间层但互不依赖。最顶层的 engine 和 rpc 将所有组件粘合在一起。
这种分层不是偶然的 —— 它对应了以太坊协议本身的分层(EL/DL/CL),也是 AI 批量生成代码时自然产生的结构:当你告诉 AI “实现 PeerDAS”,它不需要知道 ePBS 是怎么实现的,只需要知道 blob 的类型定义。模块间的低耦合,恰好让 AI 可以用 757 个子 agent 并行生成不同的包。
第三部分:AI 辅助开发的方法论
ETH2030 的作者 YQ 在另一条推文中总结了他 18 个月、90 亿 token、36 个代码库、$25,000+ API 成本的 AI coding 经验。其中一句话最为精辟:
“如果你知道如何构建某物,agent 会以 100 倍速度完成它。如果你不知道,agent 会以 100 倍速度产生有信心的垃圾。”
ETH2030 恰好是前半句的极端案例。
先决条件:人类必须懂架构
回看 ETH2030 的 commit 历史,有一个清晰的节奏:
| 阶段 | 日期 | 做了什么 | 谁在主导 |
|---|---|---|---|
| 架构设计 | 2/16-19 | 定义 50 个包的边界、类型系统、依赖关系 | 人类 |
| 批量生成 | 2/20-21 | “add 120 files across 17 packages”,LOC 从 0 到 305K | AI(757 个子 agent) |
| 集成验证 | 2/22 | 接入 go-ethereum,跑通 36,126 个 EF 测试 | 人类决策 + AI 执行 |
| 完善收尾 | 2/23-25 | 密码学完善、devnet 配置、文档 | 协作 |
关键洞察:批量生成阶段之前,架构已经确定了。 50 个包怎么分、类型定义是什么、包之间的依赖方向 —— 这些决策不是 AI 做的。AI 做的是在这个骨架上填充实现代码。
这也解释了为什么 ETH2030 的模块质量参差不齐:作者对以太坊协议非常熟悉,架构决策是对的(双层 EVM、模块分层、geth 集成方式),但 757 个子 agent 各自生成的代码,只能做到”结构正确” —— 因为 AI 不具备作者的全局判断力。
工作流:人类做决策,AI 做实现
YQ 总结的工作流是:
- 人类决定构建什么 — 架构、包边界、核心类型
- 人类写精确的 15 步分解说明 — 不是”实现 PeerDAS”,而是”在
pkg/das/sampling.go中实现GetCustodyGroups函数,输入 node ID 和 custody group count,输出该节点负责的列索引列表” - AI 处理其余部分 — 代码生成、测试编写、bug 修复
- 人类审查和集成 — 确保模块间接口一致
ETH2030 的数字印证了这个模式:
| 指标 | 数据 |
|---|---|
| Session 文件 | 765 个(8 主 + 757 子 agent) |
| API 调用 | 26,798 次 |
| 总 token | 27.7 亿(计费) |
| 成本 | ~$5,750 |
| 每千行成本 | ~$8.19 |
8 个主 session 对 757 个子 agent —— 这个比例说明了一切。8 个主 session 是人类在做架构决策和集成协调,757 个子 agent 是 AI 在并行填充各个模块的实现。
100 倍速度的代价
这种工作流的效率是惊人的:$5,750、一周、一个人,产出 50 个包、713K 行代码、18K+ 测试。但它有一个隐含的前提 —— 作者必须已经知道以太坊客户端应该长什么样。
如果换一个不懂以太坊协议的人,给同样的预算和工具,结果会截然不同。AI 会很快生成大量看似合理的代码,但架构决策会是错的 —— 包的边界不对、类型设计不对、模块间的依赖方向不对。这些错误在代码量小的时候还能修,到了 70 万行就无法挽回了。
这就是 YQ 那句话的完整含义:AI 是一个 100 倍速的放大器,它放大的是你已有的能力 —— 不管是正确的能力还是错误的能力。
总结
ETH2030 同时展示了两件事。
作为以太坊技术的参考实现,它将 2030 路线图的 65 个项目从 spec 文字变成了可编译的 Go 代码。对于想理解 3SF、PeerDAS、ePBS、zkVM 这些概念的开发者来说,读一个有类型定义和测试的代码库,比读 EIP 文本更直观。
作为 AI 辅助开发的案例,它展示了一种新的工作模式:人类做架构决策,AI 做批量实现。$5,750 和一周时间产出 50 个包 —— 这个效率意味着,未来的协议讨论可能不再只停留在 spec 和伪代码,而是直接附上一个可运行的参考实现。
但 ETH2030 也提醒我们:AI 不能替代领域知识。 这个项目之所以成立,不是因为 Claude Code 有多强,而是因为背后的人真正理解以太坊协议应该怎么构建。工具变了,但”先理解问题再写代码”这件事没变。